八股速记
八股速记
1 大模型基础
1.1 分词
- 分词:本质就是要覆盖所有语料的情况下,分得尽可能少,分得有语义
- 分词的粒度:词粒度、字符粒度、子词粒度
- **Byte Pair Encoding(BPE)**:首先基于基础词表统计词出现的次数,然后再将两个连续的词或者字符,从高频到低频进行合并。词表大小是先增加后减少的。
- Byte-level BPE(BBPE):由于字符级别的分词,在日语或者汉字中的稀有词太多,导致词表很大,所以用字节来进行编码,减少词表,防止OOV。
- WordPiece:BPE和BBPE经常会有无语义的分词,WordPiece根据互信息对连续子词进行合并。score = p(z)/p(x)p(y),让被合并的子词尽可能低频,同时合并后的高频。
- Unigram Language Model(ULM):ULM的思路是“分裂”,初始化大单元,然后根据大单元不同拆分方式中,子词的最大似然度(子词频率乘积)计算loss,倾向于保留那些以较高频率出现在很多分词结果中的子词。
- 常用分词库:SentencePiece(支持无空格语言), Tokenizers(Hugging Face,预分词)
1.2 Embedding 词嵌入
本质就是将自然语言的词,单射且同构地将高维度的数据转换为低纬度的向量,以便于计算机理解。具体来说,就是随机化初始向量形成可学习参数矩阵,以onehot为输入,向量为输出。
- OneHot:只有0 1数值,本质上是一种编码,极度稀疏,会造成词的维度爆炸。
- Word2Vec:将词映射到向量上,有两种思路
- CBOW:上下文 → 目标词(多对一),训得快,但语义捕捉弱。
- Skip-gram:目标词 → 上下文(一对多),训得慢,但语义捕捉强。
- Word2Vec加速方法:
- 霍夫曼树:避免计算所有词的softmax概率,根据词频来建立树,将多分类问题转为二分类。计算量从V变成了logV。
- 负采样:每次取一个正样本,随机取五个副样本进行权重更新。
- FastText:快速文本分类,和CBOW一样,不过输入是多个单词对和对应文档的n-gram特征,输出是文档类别,也是用了霍夫曼树的层次softmax。
1.3 注意力
Softmax:多个值映射到0-1区间内
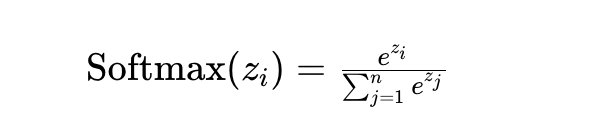
Sigmoid:将一个值映射到0-1区间内
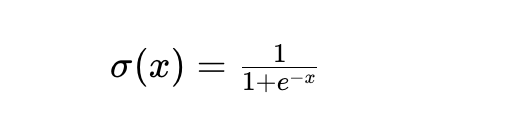
自注意力:在预测下一个词时,动态分配过去词的注意力权重
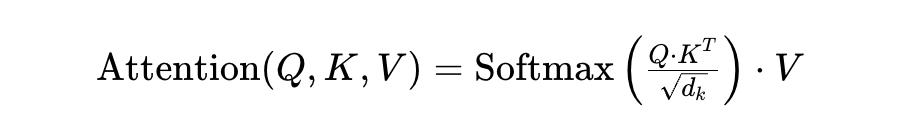
交叉注意力:QKV不是来自一个序列,而是来自不同序列,在机器翻译上比较好使。
多头注意力:将词的嵌入向量沿着特征维度拆成几个,分别QKV,这样有助于学习到词在不同维度的语义。
特征维度(hidden size):就是embedding向量的长度。
Spare attention 稀疏注意力:除了相对距离不超过k的,k 2k 3k都设置为0,局部紧密相关和远程稀疏相关,减少计算量。
线性注意力:将softmax拿掉,算法复杂度从平方转换成线性。
公式:这里分母底下的全1向量用于求和QK,从而进行归一化。
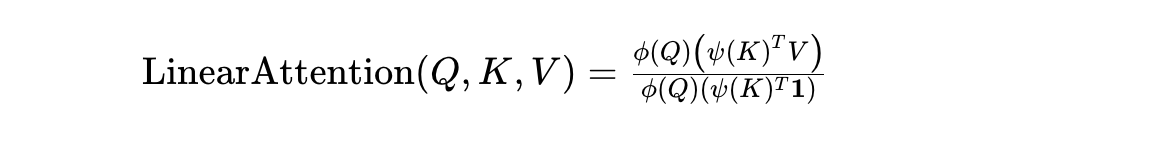
核函数:将向量矩阵从高维到低维,或者低维到高维。这里常见的有:

KV Cache:causal attention的下一个词预测计算需要用到前面的KV,使用缓存加速。
- causal attention,因果注意力,也就是当前主流的Musk掩码,在预测下一个词时,只知道前面的词。
Dual Chunk Attention:长序列固定拆块儿,块内计算QKV,块儿之间再算一遍,可以有效处理长文本。
1.4 FNN & ADD & LN
FNN 前馈神经网络:提取QKV得到的矩阵的信息,一般由俩全连接层和一个非线性激活层组成。
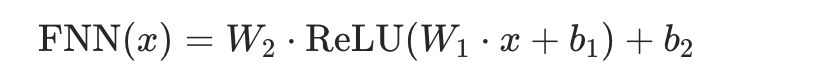
ADD 残差连接:将子层的输入和输出相加,缓解梯度消失。
LN 层归一化:将特征分布拉到0附近,标准化。
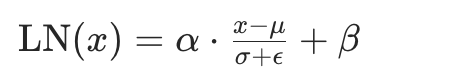
1.5 位置编码
- 绝对位置编码:transformer的经典正余弦位置编码,将每个位置的token固定一个编码,加到embeding矩阵中去。

相对位置编码:例如旋转位置编码RoPE,对Q K矩阵注入了旋转信息。
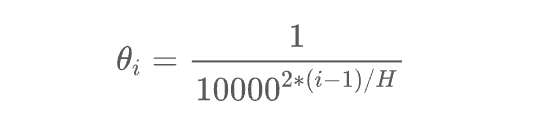
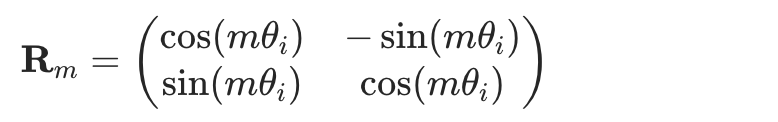
1.6 结构和解码
Encoder:MHA+FFN+ADD&LN,双向注意力,预测下一个词不做Musk。
Decoder:Masked MHA+LN&ADD,单向注意力,预测下一个词只能用之前的信息。
Dense Model 稠密模型:每次推理会激活全部参数。
场景选择:
1. 文本分类、实体识别:Encoder-only 双向注意力
1. 文本生成:Decoder-Only 单向注意力。
1. 序列到序列任务,如典型的翻译场景:输入双向、输出单向。MOE 混合专家:门控网络来决定激活那些专家网络,也就是FNN层。
解码策略:
- 选取概率最高的Token:会使得输出文本单调且重复。
- Top-K Sampling:从排名前K的token中进行抽样。
2 预训练
2.1 数据处理
- 获取URL
- 使用正则表达式进行URL过滤
- 内容抽取
- 语言识别,使用FastText过滤非语言部分
- 低质过滤,正则、困惑度等
- 模型打分,用Bert-base/FastText进行微调评分
- 数据去重,分unit,先unit内再unit之间去重
- 筛选垂域数据,关键词初筛、相似度召回、人工筛选、用这部分高质量数据训分类器、筛更多数据
2.2 预训练流程
- 训练tokeniser
- 词表扩充
- 确定模型结构和参数
- 训练框架选择、训练参数调整
- 监控训练
- 继续预训练
2.3 预训练评估
PPL困惑度:主要评估模型在预测下一个词的概率是否分散
BenchMark
大海捞针
概率探针
3 后训练
3.1 SFT 监督微调
本质就是让掌握了通用知识的大模型,可以通过指令遵循的方式,执行工作。
几个SFT共识:
prompt的质量和多样性极端重要,数量需求比较少。
可以加点预训练数据进去,减轻灾难性遗忘
不能做太多知识注入,不能有太多超过模型本身能力的问答对
合成数据:
- 通过GPT4进行合成问答对数据
- 拒绝采样,一个问题多个推理路径,Chosen 和 Rejected偏好数据,然后进行SFT或者DPO
数据质量过滤:
- 用OpenAssistant的reward model打分
- 用K - Center - Greedy算法进行过滤,最大化多样性最小化数据集
多样性包括prompt的表达方式、难度、长度,answer的长度、多样性,多轮聊天的切换topic能力
SFT训练:一般采用OpenRLHF框架,常用参数如下:
参数名 说明 设置建议 epoch 训练数据遍历模型的轮数 通常设为 1;微调垂域模型且数据量 ≤1 万条时,可设为 3 gradient_accumulation_steps 梯度累积步数,全局批量大小 = 该值 × 单设备批量 × 设备数 根据实际计算资源与批量需求调整 global_batch_size 所有设备上的总批量大小(Megatron 参数) 由单设备批量、设备数、gradient_accumulation_steps 计算,DeepSpeed 有类似设置(如 micro_train_batch_size 与 train_batch_size) learning_rate 控制模型参数更新步长 SFT 阶段通常为预训练阶段的 10 倍(如预训练 (1.5e-6),SFT 用 (3e-5)) lr_scheduler_type 学习率随训练变化的策略 常用 cosine(余弦衰减) dropout 随机丢弃神经元防止过拟合的正则化技术 一般不启用(效果有限且拖累训练效率) SFT评估:Model来评、人评
3.2 RL强化学习
强化学习本质是找到一个动作执行策略,在给定的环境下拿到最大的奖励。
马尔可夫决策:前一个状态影响后一个状态
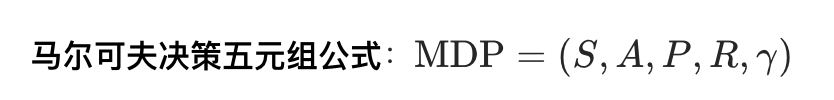

- 贝尔曼最优方程:描述选择的动作最优策略,本质是递归

蒙特卡洛方法:其实就是大数定律,样本量足够多时能代表真实概率,在大模型RL这里就是对一个策略走多个路径,来近似未来奖励期望。
动态规划方法:适用于及其清晰的环境,其中MDP和环境动态完全已知,最优策略直接DP就可以了。
时序差分方法:适用于环境不能已知,需要走一步看一步的场景。而且也比蒙特卡洛高效,因为不用等路径走完。核心思想是用未来动作选择的价值估计,更新当前动作选择的价值估计。

Q-Learning方法:选下一个价值最高的动作+即时奖励,作为当前状态最优动作的估计,属于时序差分的一种应用。
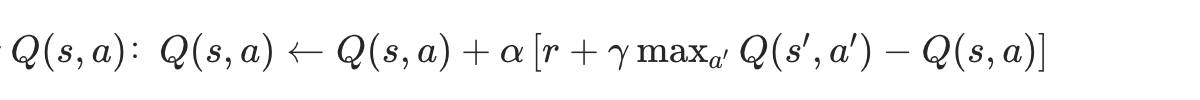
RL种类划分:
Online/Offline:一边与环境交互形成轨迹,一边学习策略;轨迹已经定好,不涉及环境交互;
Model-base/Model-free:环境转移方程、奖励函数模型构建好了,也不需要真正与环境交互;没有转移方程和奖励模型,需要直接和环境交互;
On-Policy/Off-Policy:行为策略和目标策略一致;不一致;
- 行为策略:实际用于选择动作的策略,On-Policy每一次都会根据当前行为策略选择之后的路径。
- 目标策略:利用行为策略生成的数据进行学习和更新的策略,Off-Policy中,比如Q-learning每一次都用贪婪策略模拟之后的路径。
Value-based/Policy-based:先学习值函数再导出策略;直接学习策略。
DQN Deep Q Network:适用于状态动作空间很大的场景,用表格法来表示Q值已经不行了。用俩神经网络,一个是main,根据target的输出来不断更新;一个是target,使用Q-Learning输出,定期更新到main的参数,分俩模型是为了让训练更稳定。
损失函数如下:
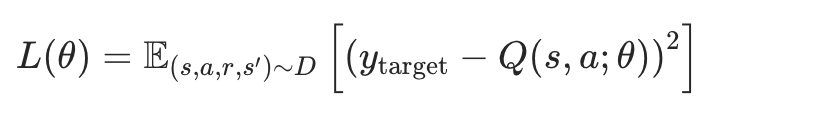
ReinForce:target的输出是用蒙特卡洛方法。
Actor-Crictic:Actor和环境交互采样,Crictic评价Actor的表现,给出优化方向。
Crictic是学习一个Q值网络,得到基于Q值的评估函数,但在连续动作空间下,要找到Q的极值计算极其复杂。
Actor可以用概率分布表示连续动作区间,因此通过Crictic进行损失函数计算后,可以通过策略函数指导更新的步长和方向。
数学过程:时序差分计算价值,更新crictic值函数,更新actor策略函数。
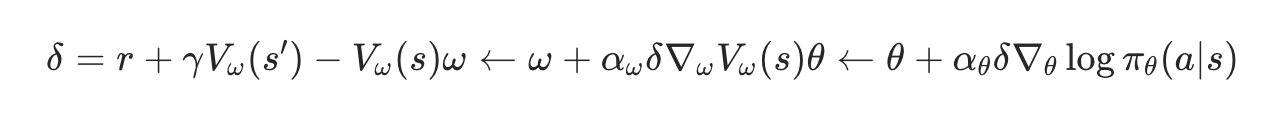
PPO算法 Proximal Policy Optimization:在Actor-Cricric损失函数这里引入了新旧策略比值裁剪,控制更新阈值,防止函数突然变坏;
数学过程:计算CLIP损失,计算值损失,计算总损失并更新策略函数。
计算值损失这里采用了正则化,保证策略的多样性探索。
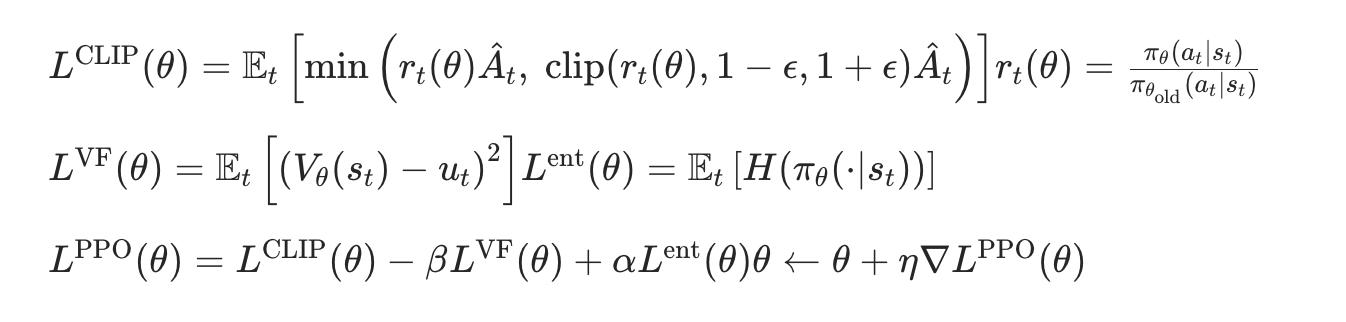
3.3 RLHF
组成:Actor、Critic、Reward、Refernece 四个模型
Actor Model:通过prompt+response计算loss
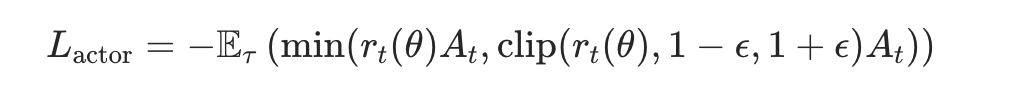
Crictic Model:对actor的动作进行价值评估,给出Actor的策略更新梯度方向
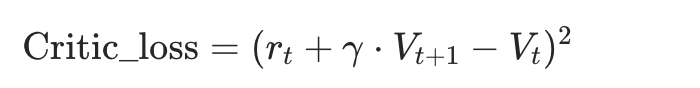
Reward Model:对response给出奖励值
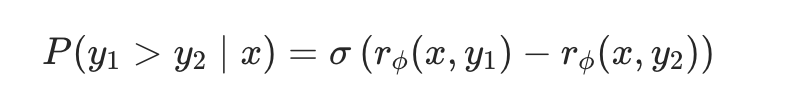
Refernce Model:一般用SFT得到的模型,它的参数是冻结的,用来产生per-token的KL约束,防止Actor Model偏离SFT太远。
Online RLHF/ Offline RLHF:轨迹自己生成/输入既定的问答对,Offline极度依赖于输入问答对和模型能力的相近度,训得会快很多。
RLAIF:训练Reword Model的问答对是AI给出的。
GRPO:核心是对相同问题用之前的策略采样多个输出,用平均奖励值来估计优势函数。
PRM 过程奖励:不必生成完整的response,reward model就可以评分。
ORM 结果奖励:通过完整的response进行打分。
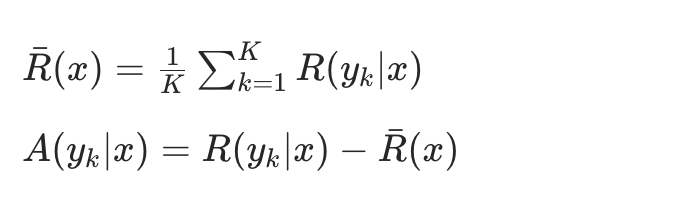
ReMax:类似GRPO,不过是使用蒙特卡洛的思路,再减去BaseLine进行回报估计。
DAPO:对GRPO的优化,具体如下:
- Clip阈值提高,增强新策略更新幅度;
- 动态采样,同一个group内过滤掉准确度0和1的输出,减少梯度消失的现象;
- loss是按group内所有token平均,而非grpo那种先output平均再平均一次,增强了长输出的贡献比例,训练更稳定;
- 对过长回答奖励进行惩罚;
DPO 直接偏好优化:PPO需要引入四个模型,而DPO直接用标签训SFT后的模型。总体目标是让模型更有可能生成偏好样本,更不可能生成拒绝样本。
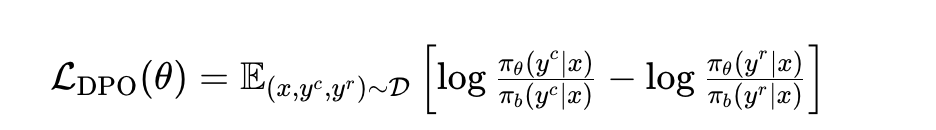
3.4 PEFT 参数高效微调
提示词微调:模型参数冻结,调整prompt
- Hard Prompt:人类直接构建提示词,在词表中挑选固定组合拼接过去。
- Soft Prompt:提示词作为可训练参数,参与梯度下降和反向传播。
P-Tuning:属于soft prompt,在embedding层加了MLP+LSTM结构。
P-Tuning V2:在每一层都留了一段前缀的位置放入向量,可以学习。
Adaptor:增加一个低阶的Adaptor层,冻结模型矩阵参数,更新这个Adaptor层。但这要更新的也蛮多,而且会增加推理时间。
Lora:将权重矩阵低秩分解成两个矩阵,更新这俩矩阵就行,由于秩远远低于原权重矩阵,因此大幅减少了计算时间,同时不会减少推理时间。
4 常见模型
4.1 Bert
由Encoder组成,关注句子本身的特征语义,主要用于情感识别和文本分类
输入:以句子对的形式

自回归语言建模:单向预测,即从左到右或从右到左预测下一个词。
自编码语言建模:类似完形填空,根据左右两边的词预测中间的词。
Bert是自编码语言建模形式,具体是通过MASK随机屏蔽15%的词实现的。
NSP next sentence possibe:输入句子对,判断俩句子是否连续。
4.2 GPT
GPT1:采用了Decoder Only的自回归语言建模,可训练的位置编码矩阵,提出了自监督预训练和有监督微调。
GPT2:post-norm改为pre-norm,用了更大的数据集,验证了足够大的自监督预训练可以迁移到其它类别任务。
GPT3:运用了局部带状+远程稀疏的注意力机制,降低了计算复杂度。
4.3 Llama
Llama1:也是用pre-norm,激活函数用了SwiGLU,RoPE作为位置编码,是一个标准的自监督模型,没有任何微调。
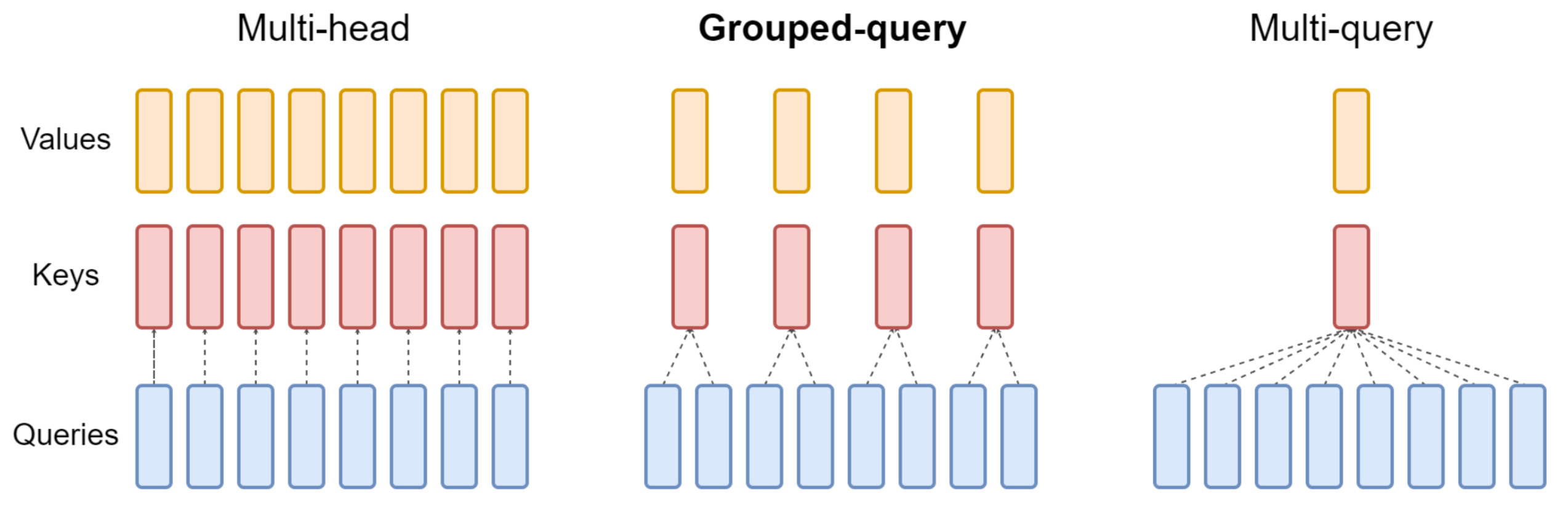
Llama2:由MQA改进到了GQA,另外扩充了FNN维度,增强了泛化能力。采用了Reject Sampling 拒绝采样。
Reject Sampling:蒙特卡洛思想,用样本逼近真实概率分布。这里是用一个prompt生成K个response,然后用reward model评分,挑选出最优的答案。
注意多次迭代,因为reward model的训练语料从当前阶段模型产生,所以每次迭代只能前进一小步。
- Llama3:架构上似乎没有特别大的变动,采用了DPO进行多轮对齐。
- Llama4:多模态,并且全面迁入MOE架构。主要是iRoPE,扩展了上下文长度。
- iRoPE:和RoPE类似,也是旋转位置编码,不过在一部分层编码,在一部分层不编码,采用动态注意力机制,通过“粗读”+“书签”的方式,提高了上下文理解能力。
- 动态注意力机制:采用向量的相似度匹配,关注那些和Query高度匹配的关键信息。
- RoPE:旋转位置编码,通过位置信息融入,来关注所有上下文,其中越近的被关注的越多。
4.3 Qwen
Qwen1:和Llama差不多,也用了RoPE,pre-norm,SwiGLU。推理部分采用了Flash Attention,加速QKV的计算并减少内存使用。
- Flash Attention:QKV分组,先计算局部QKV,然后局部softmax,同时记录最大值。最后合并结果,每个数值乘以局部最大值/全局最大值。
- 长上下文能力:
- 动态NTK插值:根据上下文长度,计算缩放因子,动态调整RoPE的的基频。
- LogN-Scaling:Query 向量(Q)进行对数长度缩放。
- 分层窗口Self-Attention:较低层使用较短窗口,较高层使用较长窗口。
Qwen2:引入了GQA、YaRN和双块注意力DCA。
- YaRN,类似动态NTK插值,也是通过缩放因子对RoPE的优化。
- DCA,长文本分块,对每个小块单独应用注意力,然后在块儿之间应用注意力。
Qwen2.5:架构上和Qwen2差不多,引入了更高质量的数据。
Qwen3:Attention层引入了RMS norm;Attention内部线性层偏移项可配置;运行时动态判断窗口大小,增加开销。
RMS norm:不用计算均值,仅归一化方差。
线性层偏移项:得出QKV的线性层中的偏执项支持配置。
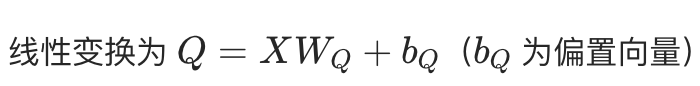
4.4 DeepSeek
DeepSeek-V1:Pre-norm、SwiGLU、RoPE、GQA、DPO
DeepSeek-V2:采用MOE架构、GRPO、MLA
- DeepSeek MOE:专家分割更细;专家隔离减少知识冗余;
- MLA:本质是低秩投影,KV矩阵下投影到缓存,再通过上投影组成原始矩阵,大幅减少了显存的利用。
DeepSeek-V3:引入共享专家的概念;引入了MTP多token预测。
- MTP:一次预测多个Token,本质是以下一个Token损失为主,融入计算后面几个Token的损失。
DeepSeek- R1:V3的链式思考形成子目标分解,用专门证明器逐个填空,形成高质量冷启动数据。
5 推理训练优化
5.1 训练推理显存分析
- 训练阶段


推理阶段
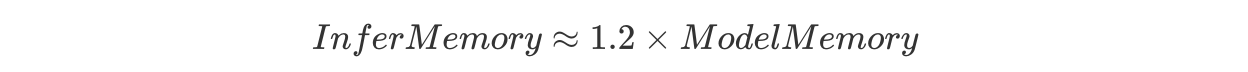
5.2 其它
PageAttention:借鉴了操作系统分页内存的思想,将kv cache分块,每个块包含固定token对应的kv cache,然后通过块表将连续的逻辑块映射到非连续的物理块。
VLLM:推理最常用的框架,分为俩阶段:
- Prefill:把整段prompt喂给模型做forward计算,并缓存kv catch。
- Decode:逐个生成token作为response。
TPS Tokens Per Second计算:


6 多模态
方法架构:
- 模态编码器:通过在大规模数据对上进行预训练,对齐视觉、音频和文本在向量空间的语义。
- 模态接口:
- BLIP-2中的Q-former:将图像特征转成token发送给LLM,好处是两边的模型参数可以冻结,只训练Q-former就行;坏处是图像特征转成token,这是有损压缩。
- 特征级融合:用MLP来拟合差距,例如LlaVA系列用一到两个MLP来投影视觉token并将特征维度和词嵌入对齐。
- 附加跨注意力层:也就是交叉注意力,用image和text标签隔开图像和文本的信息,文本对图像施加注意力、图像对文本施加注意力。
训练策略:对齐不同模态以及提供世界知识
- 两阶段训练:首先模块对齐,然后是对话和指令调优。
- 单阶段训练:直接用图像-文本对进行联合训练。
多模态对齐、融合策略:
- 双塔结构,视觉文本分别表征,通过对比学习统一语义空间度量。
- 交互型网络融合,成多模态特征。
2D-RoPE:图像和文本比起来,位置信息多了上下两个方向,因此,RoPE的方式需要做改变。我的理解是在两个正交的平面分别旋转一次。从数学公式也能看出来,是将向量拆成两半,分别旋转。